Redis(Remote Dictionary Server)是一个典型的非关系型数据库,它是开源的内存键值存储系统,也被称为数据结构服务器,支持多种数据结构(如字符串、哈希表、列表、集合、有序集合等),并提供了丰富的操作命令,可以对这些数据结构进行快速读写操作。
NoSQL 简介
主流的数据库都是关系型数据库,每次操作关系型数据库时都是 I/O 操作,I/O 操作时影响程序执行性能的主要原因之一,连接数据库和关闭数据库都是消耗性能的过程。尽量减少对数据库的连接操作,可以明显提升运行效率。
针对上面的问题,市场上出现了 NoSQL(Not Only SQL)数据库,意思是「不仅仅可以使用关系型数据库」。
常见的 NoSQL 数据库有:
- memcached:键值对,内存型数据库,所有数据都在内存中。
- Redis:和 memcached 类似,还具备持久化的能力。
- HBase:以列作为存储。
- MongoDB:以 Document 存储。
Redis 简介
Redis 是以 Key-Value 形式存储的 NoSQL 数据库。
它是使用 C 语言编写的。
Redis 的一般操作都在内存中,读写速度极快,所以常用作缓存工具使用。
Redis 也可以用作数据中心或消息队列。
Redis 以 solt(槽)作为数据存储单元,每个槽可以存储 N 个键值对,Redis 中固定有 16384 个槽。每个向 Redis 存储数据的 key 都会进行 crc16 算法后得出一个值后对 16384 取余,存放到这个结果队以哦那个的 solt。
通过 Redis Sentinel 提供高可用,通过 Redis Cluster 提供自动分区。
Redis 单机版安装和启动
Redis 的安装
-
安装 C 环境
yum install -y gcc-c++ automake autoconf libtool make tcl -
上传并解压 redis-xxx.tar.gz
tar zxvf redis-7.0.11.tar.gz -
编译并安装
make && make install PREFIX=/opt/redis -
拷贝配置文件到安装目录下
cp redis.conf /opt/redis/bin/
Redis 的启动
服务器启动
-
启动 Redis:在 /opt/redis/bin 下执行
./redis-server这种启动方式会阻塞窗口,如果不希望终端被阻塞,可以修改配置文件:
daemonize yes根据配置文件启动
./redis-server redis.conf就是非阻塞的了。
-
为了让其他地址也可以访问 redis,我们还可以在配置文件下修改:
# 取消绑定 # bind 127.0.0.1 -::1 # 关闭保护模式 protected-mode no -
根据配置文件启动:
./redis-server redis.conf
客户端启动
在 /opt/redis/bin 下执行
./redis-cli
Redis 常用的五大类型
Redis 不仅仅支持简单的 K-V 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储,它还支持数据的备份,即 master-slave 模式的数据备份,同时 Redis 支持数据的持久化,可以将内存中的数据保持在磁盘上,重启的时候可以再次加载进行使用。
Redis 支持的五大数据类型包括 String、Hash、List、Set、ZSet。
String 字符串
String 是 redis 最基本的类型,和 memcache 相同,一个 key 对应一个 value。String 类型是二进制安全的,redis 的 String 可以包含任何数据,比如 jpg 图片或序列化对象,最大能 512MB 的数据。
Hash 哈希
Redis Hash 是一个键值对集合。它是一个 String 类型的 field 和 value 的映射表,特别适合存储对象。
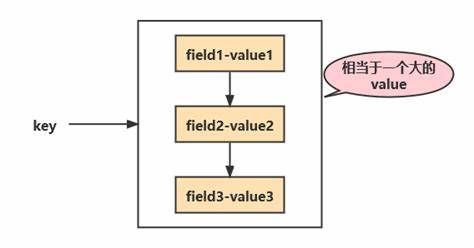
例如:需要存储这样的信息:用户 ID → 姓名、年龄、生日。
如果使用 String 存储,要么将信息封装成一个对象存储:
- set u001 "张三,18,20010101":耗费了序列化和反序列化的事件
要么分成多个键值对:
- mset user:001:name "张三" user:001:age18 user:001:birthday "20010101":又浪费了空间(多次存储 ID)
使用 Hash 就可以很好地解决这个问题。
List 列表
Redis 列表是简单的字符串列表,按照插入顺序排序,允许添加一个元素到列表的头部或者尾部。
List 的应用场景非常丰富,也是 Redis 的最重要的数据结构之一,我们可以使用 List 轻松实现最新消息排行等功能,或者实现消息队列(利用 List 的 PUSH 操作将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行)
Set 集合
Set 是字符串的无序集合。可以方便地实现交、并、补的实现,本质是一个 value 为 null 的哈希表。
利用 Set 的唯一性,可以很方便地统计出访问的所有 IP,或是共同好友。
Zset 有序集合
Zset 和 set 一样,也是 String 类型元素的集合,不同的是 zset 中每个元素会关联一个 double 类型的分数,通过分数来为集合中的成员进行从小到大的排序。
zset 是一种比较复杂的数据结构,使用的场景不算太多,适合带有权重的集合元素,例如一个游戏的得分排行榜。
Redis 常用命令
Redis 的帮助文档十分丰富,在网络上很容易找到,下面是其中一个:http://doc.redisfans.com/,下面介绍一些基本命令。
Key 操作
exists
判断 key 是否存在。
exists [key1] [key2] ...
返回值:返回存在的个数,不存在返回 0
expire
设置 key 的过期时间,单位秒
expire key [过期时间]
返回值:成功返回 1,失败返回 0
ttl
查看 key 的剩余过期时间
ttl [key]
返回值:返回剩余时间,单位秒,如果永不过期返回 -1,如果已经失效返回 -2
del
删除 key
del [key1] [key2] ...
返回值:被删除的 key 的数量
String 操作
set
设置键值对。
set [key] [value]
返回值:成功 OK
get
获取值。
get [key]
返回值:key 对应的 value 值,不存在时返回 nil
setnx
当且仅当 key 不存在时才新增。
setnx [key] [value]
返回值:新增的键值对个数,key 已存在返回 0
setex
设置 key 的键值对和存活时间,无论是否存在指定 key 都能新增,如果存在 key 就覆盖旧值,同时必须指定过期时间。
setex [key] [ttl] [value]
返回值:OK
Hash 操作
Hash 类型的值中包含多组 field-value,相当于一个 string 类型的 field 和 value 的映射表:
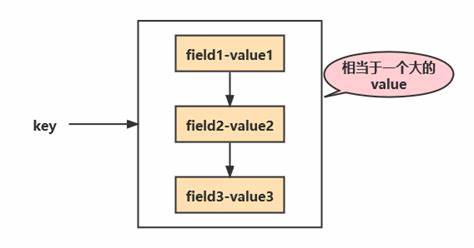
hset
给 key 中 field 设置值。
hset [key] [field] [value]
返回值:成功返回 1,失败返回 0
hget
获取 hash 中的 field 值。
hget [key] [field]
返回值:field 对应的 value,不存在返回 nil
hmset
一次设置 key 中多个 field 值。
hmset [key] [field1] [value1] [field2] [value2] ...
返回值:成功 OK
hmget
一次获取 key 中多个 field 值。
hmget [key] [field1] [field2] ...
返回值:value 列表
hvals
获取 key 中所有 field 的值。
hvals [key]
返回值:value 列表
hgetall
获取所有的 field 和 value。
hgetall [key]
返回值:field 和 value 的交替列表。
hdel
删除 key 中的若干个 field。
hdel [key] [field1] [field2] ...
返回值:成功删除 field 的数量
注意区分:
del [key]会删除整个哈希表。
List 操作
lpush / rpush
从列表左/右插入。
lpush/rpush [key] [value1] [value2] ...
返回值:插入后列表的元素个数
lpop / rpop
删除并获取表头/尾。
lpop/rpop [key]
返回值:删除的表头/尾的 value。
lrange
获取指定区间的元素值(闭区间),-1 表示最后一个成员,-2 表示倒数第二个,以此类推。
lrange [key] [left] [right]
返回值:查询到的 value 列表
llen
获取列表的长度。
llen [key]
返回值:列表的长度。
lrem
删除 count 个值为 value 的元素,count 为正,从左向右搜索;count 为负,从右向左搜索;count 为 0,删除所有值为 value 的元素。
lrem [key] [count] [value]
返回值:删除数量
Set 操作
sadd
向集合中添加内容。
sadd [key] [member1] [member2]...
返回值:添加后,集合的长度
srem
移除一个或多个成员。
srem [key] [member1] [member2] ...
返回值:成功移除的元素的数量。
scard
返回集合元素数量
scard [key]
返回值:集合长度
smembers
返回集合所有元素
smembers [key]
返回值:集合全部 member 列表
Zset 操作
zadd
向有序集合中添加内容。
zadd [key] [score1] [member1] [score2] [member2]...
返回值:新添加成功的个数,不包括被更新的成员
zrange
返回有序集合中,指定区间内的成员(按照分数升序排名),-1 表示最后一个成员,-2 表示倒数第二个,以此类推。
zrange [key] [left] [right] [withscores]
返回值:有序集合的 member 列表;如果添加 withscores,还会将分数也列出。
Redis 的持久化策略
Redis 不仅仅是一个内存型数据库,还具备持久化能力。
RDB
默认的模式。在指定时间间隔内生成数据快照,默认保存在 dump.rdb 文件中,当 redis 重启后,会自动加载 dump.rdb 中的内容到内存中。
可以采用 SAVE(同步,阻塞等待保存)或 BGSAVE(异步,在后台执行保存)手动保存数据。
可以设置服务器配置的 SAVE 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命令,可以通过 save 选项设置多个保存条件,只要其中一个被满足,服务器就会自动执行 BGSAVE 命令。例如:
save 900 1
save 300 10
save 60 10000
只要满足三个条件中的任意一个,BGSAVE 就会被执行:
- 服务器在 900 秒内,对数据库进行了至少 1 次修改。
- 服务器在 300 秒内,对数据库进行了至少 10 次修改。
- 服务器在 60 秒内,对数据库进行了至少 10000 次修改。
优点
- rdb 文件时单独的一个紧凑文件,直接使用 rdb 文件就可以还原数据
- 数据保存由子进程实现,不会影响父进程。
- 恢复数据的效率高于 aof
缺点
- 保存点之间如果 redis 意外关闭,将会丢失数据
- 每次保存数据都需要 fork 子进程,数据量较大时,可能比较耗费性能
AOF
默认关闭,需要在配置文件中启动:
# 修改为 yes
appendonly yes
# aof 文件名
appendfilename "appendonly.aof"
AOF 的原理是监听执行的命令,如果发现执行了修改数据的操作,同时直接同步到数据库文件中。
Redis 支持 AOF 和 RDB 同时生效,如果同时生效,AOF 优先级高于 RDB(重新启动时优先使用 AOF 进行数据恢复)。
优点
- 相对 RDB 数据更安全。
缺点
- 占用空间更大
- 速度更慢
Redis 主从复制
Redis 支持集群功能,为了保证单一结点的可用性,redis 支持主从复制功能。每个结点有 N 个复制品(replica),其中一个复制品是主(master),另外 N-1 个复制品是从(slave),也就是说 Redis 支持一主多从。
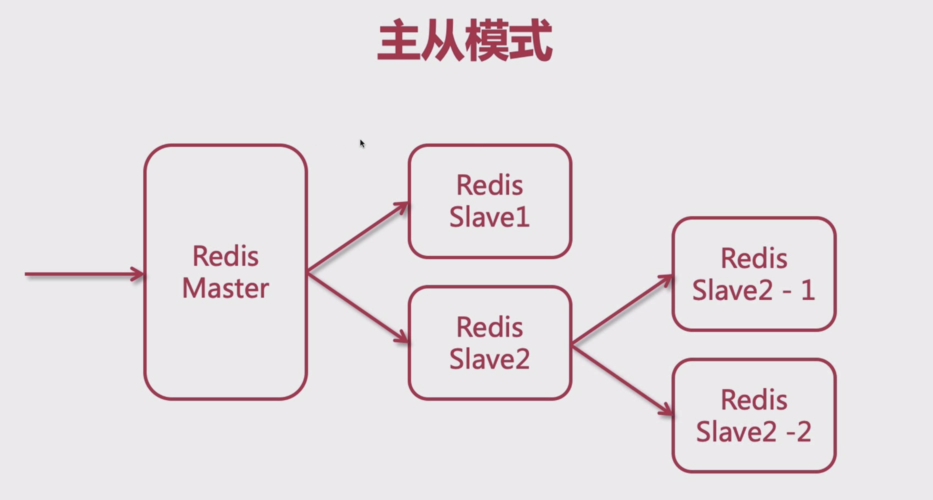
主从的优点
- 增加单一结点的健壮性,从而提升整个集群的稳定性。(当 Redis 中超过 1/2 结点不可用时,整个集群不可用)
- 从节点可以对主节点数据备份,提升容灾能力
- 读写分离:主节点一般用作写(同时具备读能力),从结点只能读,利用这个特性实现读写分离,写用主,读用从。
搭建主从集群
-
先关闭 redis 单机版
./redis-cli shutdown -
新建目录
mkdir /opt/replica -
把之前安装的 redis 单机版的 bin 目录复制三份,分别命名为 master、slave1、slave2
cp -r /opt/redis/bin /opt/replica/master cp -r /opt/redis/bin /opt/replica/slave1 cp -r /opt/redis/bin /opt/replica/slave2 -
由于我们用一台机器模拟集群,为了避免端口冲突,需要在从节点配置文件中修改端口号并配置复制:
# 修改端口号 port 6380 # 根据这个注释配置复制结点 # replicaof <masterip> <masterport> replicaof 192.168.80.130 6379类似地,修改 slave2 的端口号和复制配置。
-
为了方便,我们可以在 replica 文件夹根目录下写一个脚本 startup.sh:
./master/redis-server master/redis.conf ./slave1/redis-server slave1/redis.conf ./slave2/redis-server slave2/redis.conf启动脚本,一次启动这个集群:
sh startup.sh可以看到,三台 redis 服务器都已经启动:

-
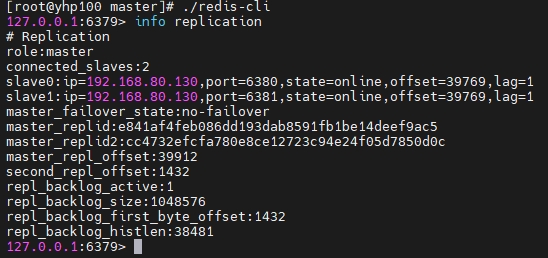
在 master 服务器的客户端,使用
info replication可以看到主从信息:
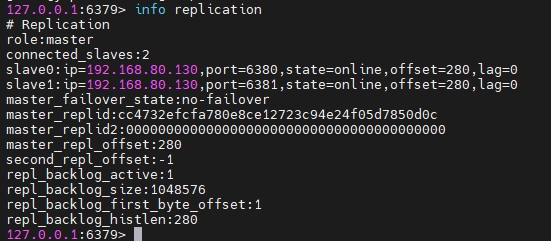
尝试在主节点写入数据:

在从节点也可以取得(注意需要使用
./redis-cli -p [从节点端口号]才能进入从节点的客户端):
从节点具备写的能力吗?
哨兵(Sentinel)
在 Redis 主从默认是只有主具备写的能力,从只负责读。如果主宕机,整个结点就不具备写的能力。但是如果让一个从变成主,整个节点又能继续工作,即使之前的主恢复过来,只需要当这个新主的从即可。
Redis 的哨兵就是帮助监控整个节点的,当主节点宕机等的情况下,帮助重新选取主。
Redis 中的哨兵支持单哨兵和多哨兵,单哨兵是只要它发现主宕机了,就直接选取另一个 master;多哨兵是根据我们设定,达到多少数量的哨兵认为 master 宕机之后才会进行重新选取主。
没有哨兵的情况
使用 kill 杀掉 master 进程,再进入从进程,仍然不具备写的能力。
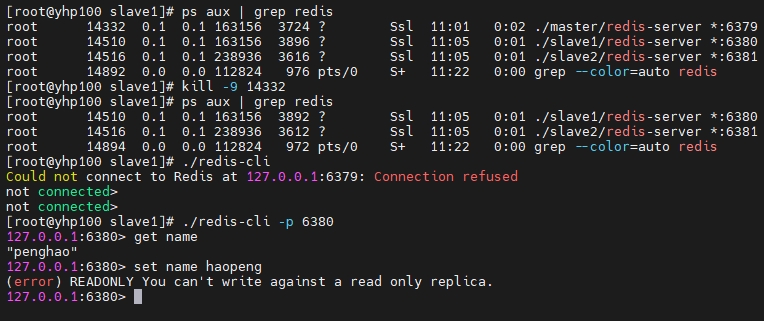
搭建多哨兵的具体步骤
-
新建目录
mkdir /opt/sentinel -
复制 Redis 到哨兵目录下
cp -r /opt//redis/bin/* sentinel/ -
在 Redis 的解压目录下,有哨兵的配置文件 sentinel.conf,把它复制到哨兵目录下:
cd /tmp/redis-7.0.11/ cp sentinel.conf /opt/sentinel/ -
修改哨兵配置文件:
# 后台启动 daemonize yes # 日志存储位置,这里是因为这个哨兵的端口号是 26379 所以这样命名 logfile "/opt/sentinel/26379.log" # 配置哨兵监听,选择主节点,2 代表配置多哨兵,只有 2 个哨兵都认为 master 宕机才会重新选主 sentinel monitor mymaster 192.168.80.130 6379 2 -
复制哨兵文件,命名为「sentinel-26380.conf」,修改配置如下:
port 26380 logfile "/opt/sentinel/26380.log"同样地,再创建一个命名为「sentinel-26381.conf」的配置并修改。
-
启动 Redis 主从
cd /opt/replica sh startup.sh -
启动哨兵
cd /opt/sentinel/ ./redis-sentinel sentinel.conf ./redis-sentinel sentinel-26380.conf ./redis-sentinel sentinel-26381.conf -
此时的状态:

主进程是 master,如果杀掉主进程:
kill -9 2927此时再进入 6380 端口的原 Slave 客户端:
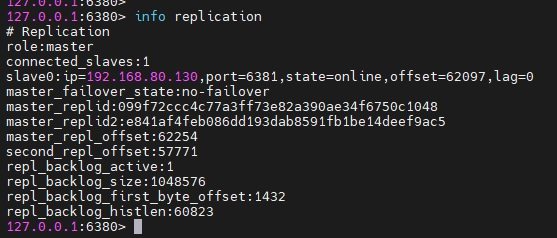
发现它已经变为主,既可以写,也可以读。
-
再次开启 master 下的 redis 服务:
./redis-server redis.conf ./redis-cli发现 master 恢复后依旧作为从,并且主是之前上位的 6380。
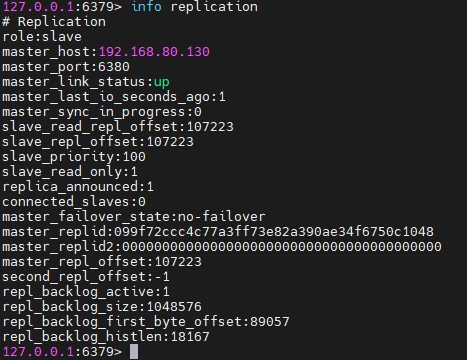
-
查看日志
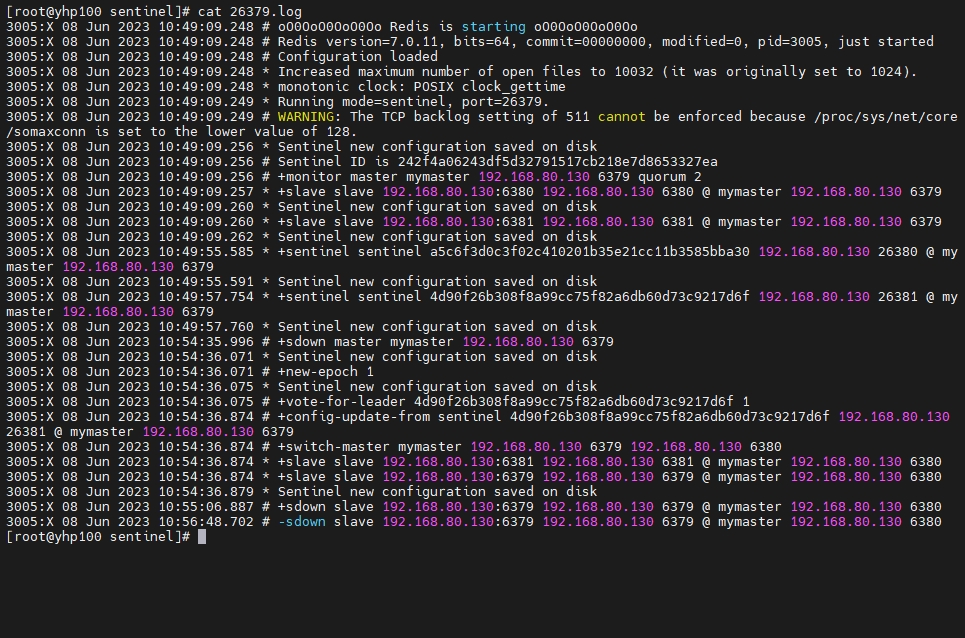
集群(Cluster)
在集群中超过或等于 1/2 节点不可用时,整个集群不可用。为了搭建稳定的集群,一般采用奇数节点。
-
复制 redis 配置文件
cp /opt/redis/bin/redis.conf /opt/redis/bin/redis-7001,conf -
修改 redis-7001.conf
port 7001 pidfile /var/run/redis_7001.pid # 集群设置 cluster-enabled yes cluster-config-file nodes-7001.conf cluster-node-timeout 15000类似地,创建 redis-7002.conf、redis-7003.conf、redis-7004.conf、redis-7005.conf
-
启动这些 redis 服务:
注意:在启动前,删除之前的 dump.rdb
创建启动脚本:
./redis-server redis-7001.conf ./redis-server redis-7002.conf ./redis-server redis-7003.conf ./redis-server redis-7004.conf ./redis-server redis-7005.conf ./redis-server redis-7006.conf启动:
chmod u+x startup.sh ./startup.sh类似地,可以写一个终止脚本 stop.sh
./redis-cli -p 7001 shutdown ./redis-cli -p 7002 shutdown ./redis-cli -p 7003 shutdown ./redis-cli -p 7004 shutdown ./redis-cli -p 7005 shutdown ./redis-cli -p 7006 shutdown -
注意:初次创建时,除了打开服务器,还必须配置集群才能让集群生效!
在 redis3 时,需要借助 ruby 脚本实现集群,现在,可以使用 redis-cli 实现集群,更加方便。
建议设置静态 ip,ip 改变集群生效。
./redis-cli --cluster create \ 192.168.80.130:7001 \ 192.168.80.130:7002 \ 192.168.80.130:7003 \ 192.168.80.130:7004 \ 192.168.80.130:7005 \ 192.168.80.130:7006 \ --cluster-replicas 1这里的含义是:创建这六个地址的集群,每个集群节点有一个复制(一主一从)。
-
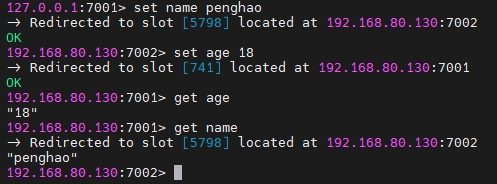
测试集群时,记得最后一个 -c 参数
./redis-cli -p 7001 -c可见,集群已经生效,其他主机也分担了查询和修改的压力,在需要其他节点出手时,会重定向:
Jedis
Jedis 是一个开源的 Java 编程语言 Redis 客户端,由 Xetorthio 开发和维护。它提供了简单易用、高性能的 API,可以连接到 Redis 服务器并执行各种操作,Jedis API 同 Redis 命令基本相同,特别简单易用。
单机版
-
创建 Maven 工程
-
导入 jedis 依赖
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.3.1</version> </dependency> -
测试
@Test public void testStandalone() { Jedis jedis = new Jedis("192.168.80.130", 6379); jedis.set("test", "penghao"); String value = jedis.get("test"); System.out.println(value); }
带连接池
@Test
public void testJedisPool() {
// 配置连接池
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(5);
jedisPoolConfig.setMinIdle(3);
// 创建连接池
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.80.130", 6379);
// 从连接池获取连接
Jedis jedis = jedisPool.getResource();
jedis.set("test2", "pool");
String test2 = jedis.get("test2");
System.out.println(test2);
}
使用集群
@Test
public void testCluster() {
Set<HostAndPort> set = new HashSet<>();
set.add(new HostAndPort("192.168.80.130", 7001));
set.add(new HostAndPort("192.168.80.130", 7002));
set.add(new HostAndPort("192.168.80.130", 7003));
set.add(new HostAndPort("192.168.80.130", 7004));
set.add(new HostAndPort("192.168.80.130", 7005));
set.add(new HostAndPort("192.168.80.130", 7006));
try (JedisCluster jedisCluster = new JedisCluster(set)) {
jedisCluster.set("name", "cluster");
String name = jedisCluster.get("name");
System.out.println(name);
}
}
使用 SpringBoot 整合 SpringDataRedis 操作 Redis
Spring Data 是 Spring 提供的对各种数据操作 API 的封装项目,它可以很方便地操作各种对象。其中一个二级项目 Spring Data Redis 对 Redis 操作进行了封装,把 Redis 不同值的类型放到一个 opsForXXX 方法中:
- opsForValue:String 值
- opsForList:List 列表
- opsForHash:Hash 哈希表
- opsForSet:Set 集合
- opsForZSet:Sorted Set 有序集合
添加依赖
在 SpringBoot 项目中使用 Redis,需要加入其启动器:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置 Redis 集群
spring:
redis:
cluster:
nodes: 192.168.80.130:7001,192.168.80.130:7002,192.168.80.130:7003,192.168.80.130:7004,192.168.80.130:7005,192.168.80.130:7006
Redis 配置类
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<Object>(Object.class));
redisTemplate.setConnectionFactory(factory);
return redisTemplate;
}
}
使用 Redis 做缓存的 Service 实现类
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductMapper mapper;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Override
public Product findProductById(Integer id) {
String key = "product:" + id;
// 先从 redis 中获取数据
if (redisTemplate.hasKey(key)) {
System.out.println("缓存命中,执行 Redis 查询");
redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer<Product>(Product.class));
return (Product) redisTemplate.opsForValue().get(key);
}
// 如果 redis 没有,再从 mybatis 获取
System.out.println("执行 MySQL 查询");
Product product = mapper.findProductById(id);
// 设置缓存
redisTemplate.opsForValue().set(key, product);
return product;
}
}